Timescale
Mais qu’est-ce que c’est ?
- Extension PostgreSQL
- Solution Open Source On Premise ou Cloud (payant)
- Adapté à l’ingestion de données de type time-series
- Partitionne les données de manière transparente pour gagner en performances
- Intègre la possibilité de faire de l’aggrégation de données en continue
- Gère la compression et rétention des données
Time-series ça veut dire quoi ?
- Une donnée dont la valeur évolue au cours du temps
- Météo, température, humidité, etc.
- Utilisation des ressources (CPU, mémoire, etc.)
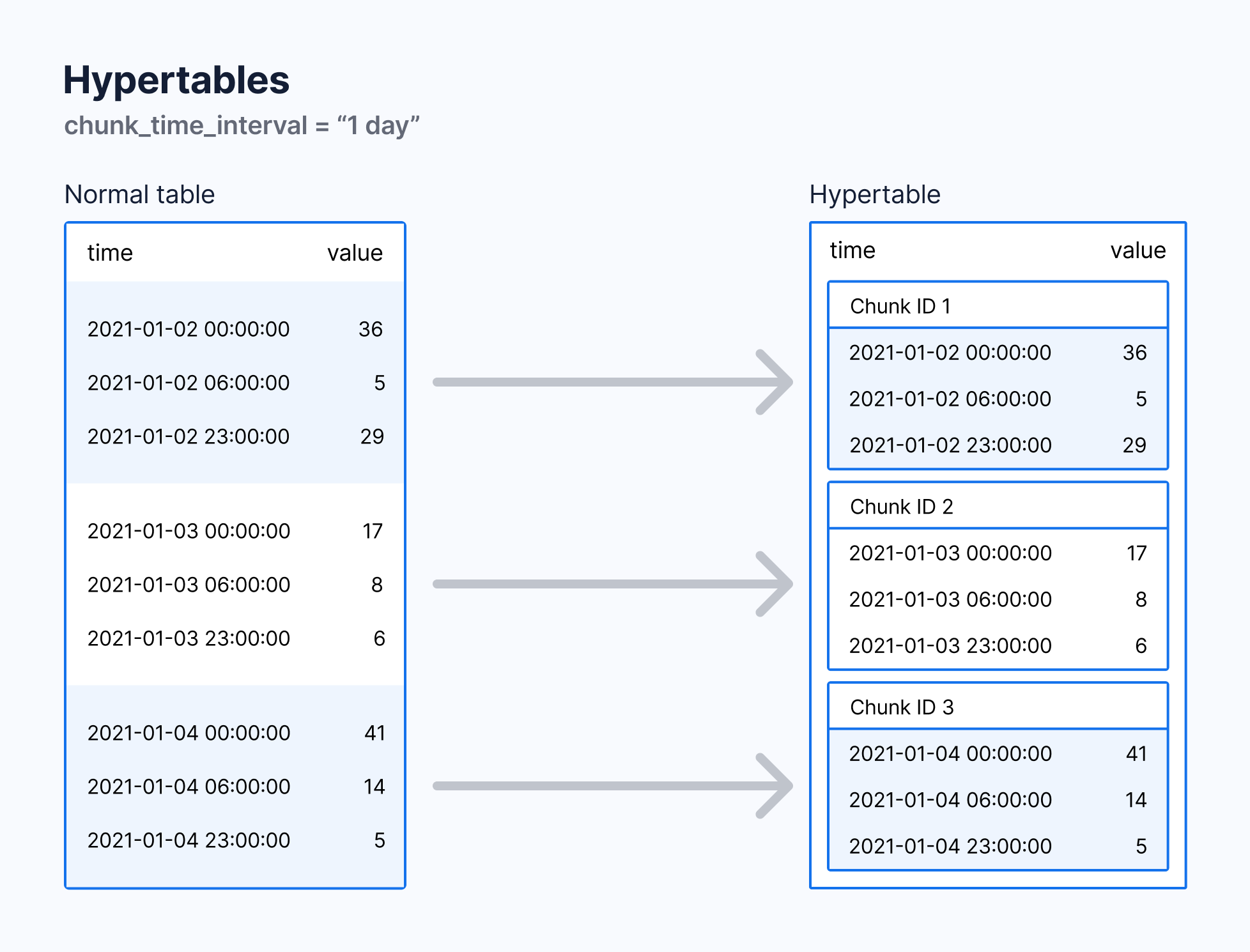
Comment partitionner les données ?
- Par la création d’une hypertable (table sur laquelle timescale se greffe)
- Une hypertable profite de toutes les fonctionnalités d’une table PostgreSQL
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
device TEXT NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
PRIMARY KEY (time, device, location)
);
SELECT create_hypertable('conditions', 'time'); -- 7 jours
SELECT create_hypertable('conditions', 'time',
chunk_time_interval => INTERVAL '1 day');
-- si modification du partitionnement plus tard
SELECT set_chunk_time_interval('conditions', INTERVAL '2 days');
- Préférer
drop_chunkspour la suppression de données en batch
De l’aggrégation continue, pourquoi faire ?

- Éviter de parcourir l’entièreté de la table live pour obtenir une donnée aggrégée
- Rafraichir les données aggrégées régulièrement (avec l’ajout de nouvelles données ou la modification d’anciennes données)
- Les aggrégations continues peuvent profiter de la compression et rétention
CREATE MATERIALIZED VIEW 'conditions_summary_hourly'
WITH (timescaledb.continuous) AS
SELECT
time_bucket('1 hour', 'time') AS bucket,
device,
location,
min(temperature) AS min_temperature,
max(temperature) AS max_temperature,
max(humidity) - min(humidity) AS humidity_spread
FROM conditions -- doit se baser sur une hypertable
GROUP BY bucket, device, location
WITH NO DATA; -- ne pas populer l'aggrégation à sa création
SELECT set_chunk_time_interval('conditions_summary_hourly',
INTERVAL '1 day');
Comment puis-je garder mon aggrégation à jour ?
- Rafraichissement récurrent d’une aggrégation continue
- Réaggrège uniquement les buckets dont les chunks associés ont changé
- Ne rafraichie pas les données les plus récentes (real time)
SELECT add_continuous_aggregate_policy('conditions_summary_hourly',
start_offset => INTERVAL '1 month',
-- recommandé de s'arrêter avant le dernier *bucket*
end_offset => INTERVAL '1 hour',
schedule_interval => INTERVAL '1 hour');
-- rafraîchir manuellement l'aggrégation (date de fin non comprise)
CALL refresh_continuous_aggregate('conditions_summary_hourly',
'2024-08-01',
'2024-09-01');
Et si je veux mes données en temps réel ?
ALTER MATERIALIZED VIEW 'conditions_summary_hourly'
SET (timescaledb.materialized_only = false);

Compression, késako ?
- Compresser les plus anciennes données pour gagner de l’espace disque
- Décompression des chunks lors de requêtes sur les zones compressées
- Utiliser
compress_segmentbypour de meilleurs temps
-- pour compresser une hypertable
ALTER TABLE conditions SET (timescaledb.compress,
timescaledb.compress_orderby = 'time DESC'
timescaledb.compress_segmentby = 'device, location');
-- définition de l'ancienneté des données avant compression
SELECT add_compression_policy('conditions', INTERVAL '2 months');
-- pour compresser une aggrégation continue
ALTER MATERIALIZED VIEW 'conditions_summary_hourly'
SET (timescaledb.compress = true);
SELECT add_compression_policy('conditions_summary_hourly',
compress_after => '2 months'::INTERVAL);
Rétention, késako ?
- Supprimer les plus anciennes données pour stabiliser l’espace disque
- Aussi possible avec les aggrégations continues
-- définition de la durée de rétention
SELECT add_retention_policy('conditions', INTERVAL '6 months')
Quelles limitations ?
- Décompression de tous les chunks à l’ajout d’un champ obligatoire ou valeur par défaut
- Un chunk en cours de décompression prendra sa place compressée et sa place décompressée jusqu’à décompression complète
- Obligation de supprimer et recréer une aggrégation continue lors d’un changement de schéma